
Big Data Lake Solution for Warehousing Stock Data and Tweet Data
Created by Stuart Miller, Paul Adams, and Rikel Djoko
Project Summary
The objective of this project was to build a large-scale data framework that will enable us to store and analyze financial market data as well as drive future predictions for investment.
For this project, the following types of data were used
- Daily stock prices for all companies traded on the NYSE and the NASDAQ.
- Intra-day values for all companies traded on the NYSE and the NASDAQ.
- Prices: high, low, open, close,
- Supporting Values: Brollinger Bands, stochastic oscillators, and moving average CD
- Intra-day values are at 15 minute intervals
- Tweets from over 100 investment related twitter accounts
Data Warehouse Overview
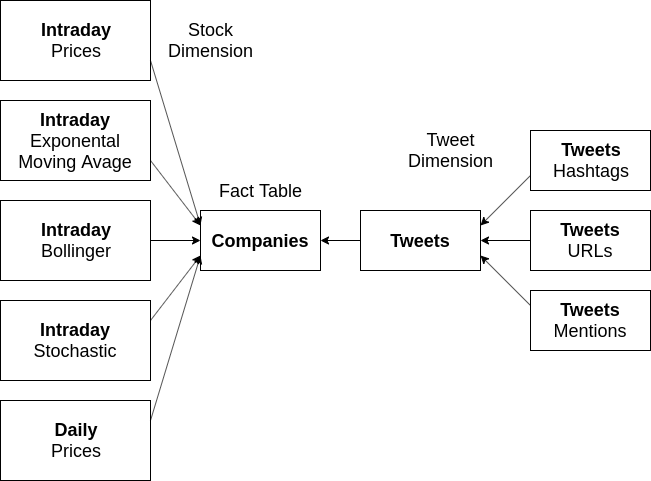
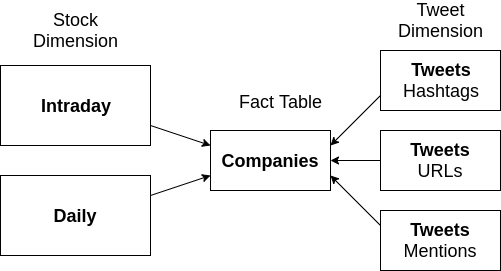
Two star schemas were designed for this data warehouse: a normalized schema (3NF) and a denormalized schema (1NF). We investigated the performance of the two schemas in the context of this problem. Conceptual diagrams of the data warehouse schemas are shown below.
Conceptual Diagram of the Data Warehouse Snowflake Schema
Conceptual Diagram of the Data Warehouse Denormalized Star Schema
Big Data Solution Implementation
Data Collection
Data collection was operated by an AWS elastic compute 2 (EC2) instance. It queried Twitter data from the Twitter API and stock data from the AlphaVantage API. As the data was collected, it was pushed into a long-term storage archive. The data collection systems were implemented in R and python.
Data Storage (Long-term)
For data storage, AWS S3 was used. It is used to store and retrieve any amount of data any time, from anywhere on the web. S3 is reliable, fast, and inexpensive. S3 was used to share and load data directly into HDFS.
Data Lake Implementation
The data was trasferred into a Hadoop data lake for this project. Elastic MapReduce (EMR), from AWS, was used for the implementation of Hadoop in this project. AWS EMR is a pre-configured compute cluster for Big Data. The cluster can be provisioned and terminated on demand. It comes with a configurable set of the Hadoop ecosystem elements pre-installed and ready to use. The EMR cluster used in this study was provisioned with three m5.xlarge elastic compute instances using version 5.27.0 of the EMR software. Apache Hive was used to create the data warehouse from the data lake. Cloudera Hue was used to interface with the Hadoop cluster.
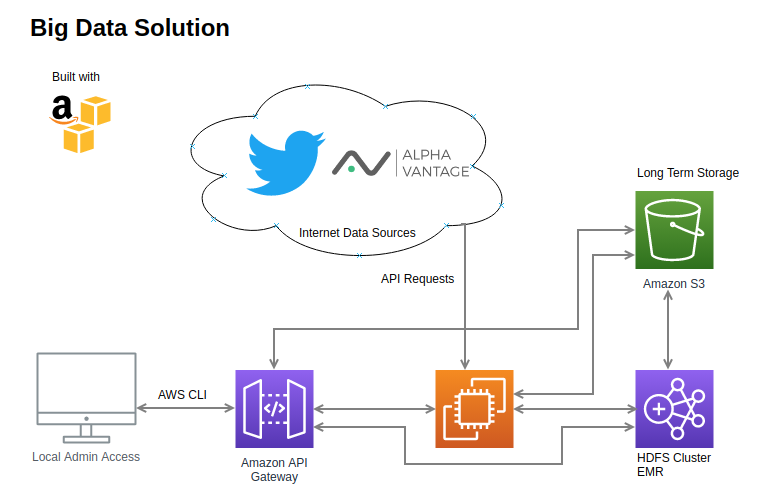
More information about Amazon Web Serves can be found at https://aws.amazon.com/
Results
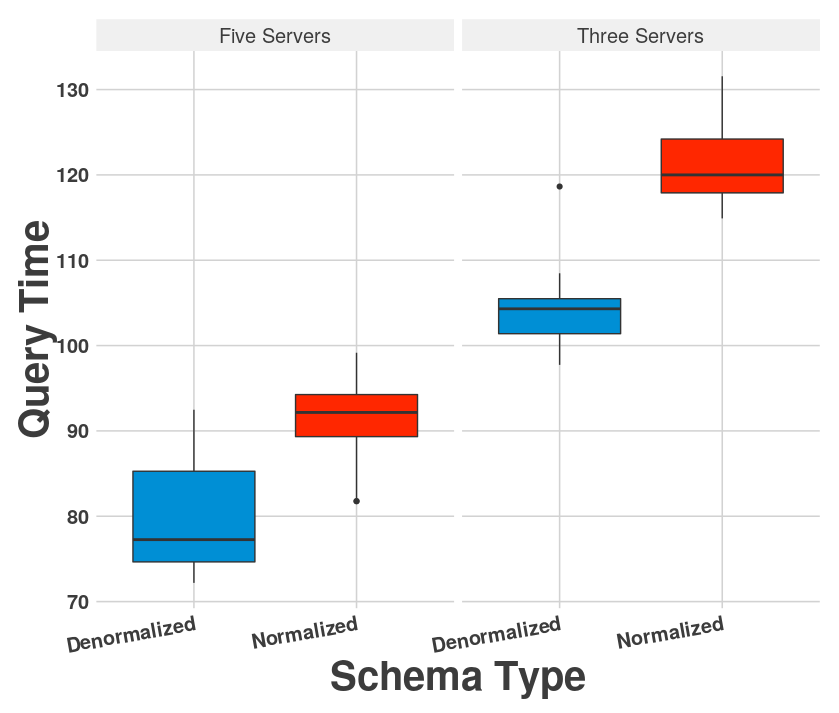
Queries were run on the two schemas with different EMR cluster sizes to see the impact of normalization on query time. The collected data is located here. A plot summarizing the results is shown below.
Additional Information
- The project repository can be found at https://github.com/sjmiller8182/Warehousing-Stock-Tweet-Data
- The project paper can be found here